




















انتخاب ویژگی و طبقه بندی داده های بیماری با MATLAB
در این بخش پروژه انتخاب ویژگی و طبقه بندی داده های بیماری با الگوریتم KNN و بهینه سازی ترکیبی (GOA و SA) در نرم افزار MATLAB آماده کرده ایم که در ادامه توضیحاتی از معرفی پروژه ارائه شده و فیلم و تصاویر خروجی پروژه در محیط متلب قرار داده شده است.
معرفی پروژه
در این پروژه الگوریتم طبقه بندی KNN یا الگوریتم k نزدیکترین همسایه برای آموزش و طبقه بندی مجموعه داده های بیماری های پزشکی مانند سرطان پستان ، ضربان قلب ، داده های لیموگرافی و غیره پیاده سازی می شود. برای بهبود دقت طبقه بندی و کاهش سربار محاسباتی ، الگوریتم بهینه سازی ملخ (GOA) و الگوریتم شبیه سازی تبرید (SA) برای انتخاب بهینه ویژگی ها از پایگاه داده مورد استفاده قرار گرفته است.
انتخاب ویژگی در یادگیری ماشین
فرایند انتخاب ویژگی در یادگیری ماشین برای کاهش هزینه های اضافی و بهبود دقت بسیار مهم است. روش های مختلفی تاکنون پیشنهاد شده است اما روش های بهینه سازی فراابتکاری در این روش ها پیشرو هستند. از این رو ما یک الگوریتم بهینه سازی ترکیبی جدید را در این پروژه مورد استفاده قرار دادیم که ترکیبی از الگوریتم بهینه سازی ملخ (GoA) و الگوریتم شبیه سازی تبرید (SA) است. روند انتخاب ویژگی مبتنی بر باینری سازی الگوریتم های بهینه سازی است. شاخص های ویژگی ها در صورت انتخاب یا عدم انتخاب به ترتیب 1 یا 0 هستند. ماتریس با آرایش 1 و 0 وارد الگوریتم بهینه سازی می شود.
از آنجا که روش GoA برای پذیرش ورودی باینری ساخته نشده است ، بنابراین موقعیت های اولیه گرگ ها را در GoA گرد می کنیم. این کار موقعیت های GoA را 1 و 0 می کند. این موضوع نمایانگر شاخصه های انتخاب شده است زیرا بُعد موقعیت گرگ برابر با تعداد ویژگی های پایگاه داده می باشد. علاوه بر این ، موقعیت به روز شده GoA نیز با تابع signum به باینری تبدیل می شود. موقعیت دودویی نهایی انتخاب شده GoA ، شاخص ویژگی های انتخاب شده می باشد که با استفاده از الگوریتم k نزدیکترین همسایه طبقه بندی می شود.
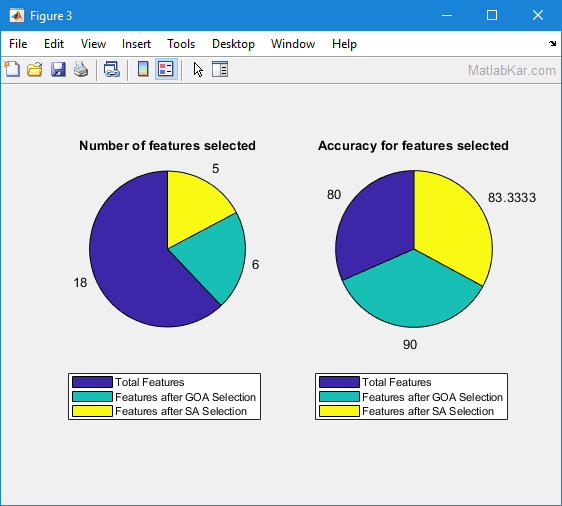
تصاویری از خروجی




 در متلب")
 در متلب")
 در متلب")
 در متلب")


")




هیچ نظری ثبت نشده است